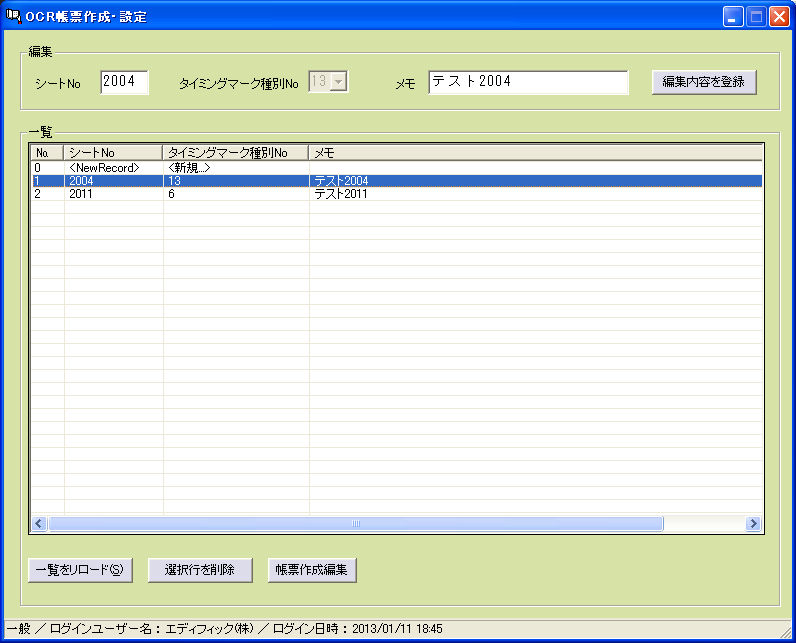
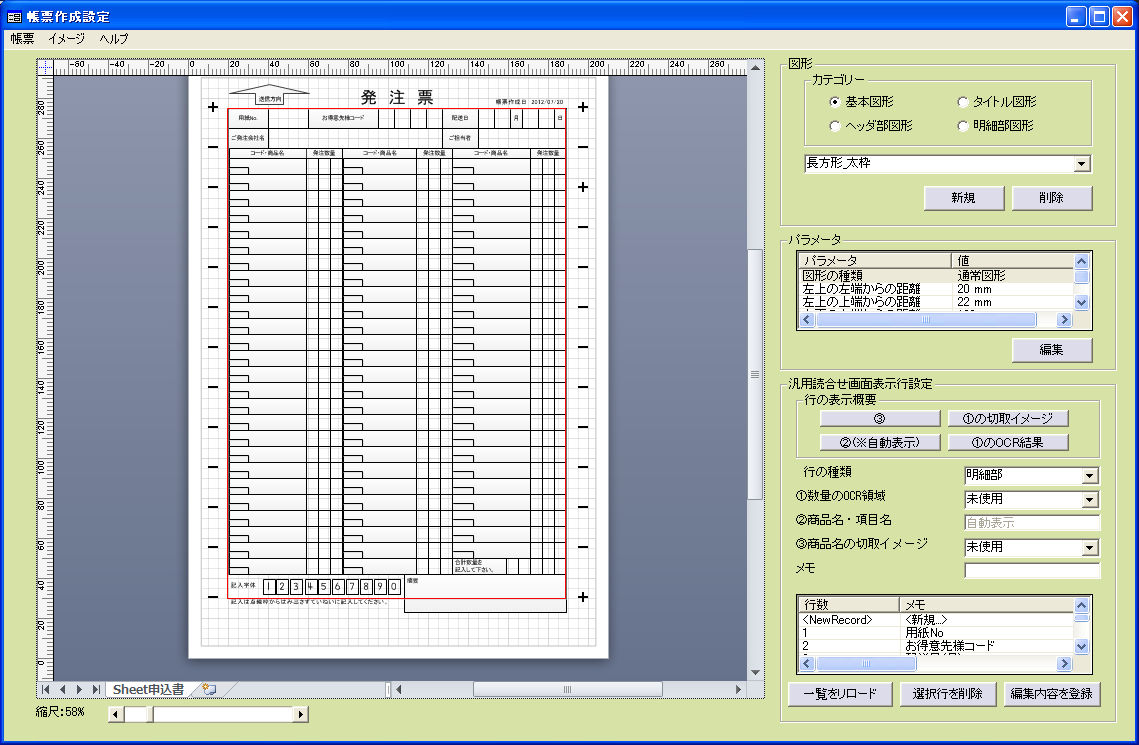
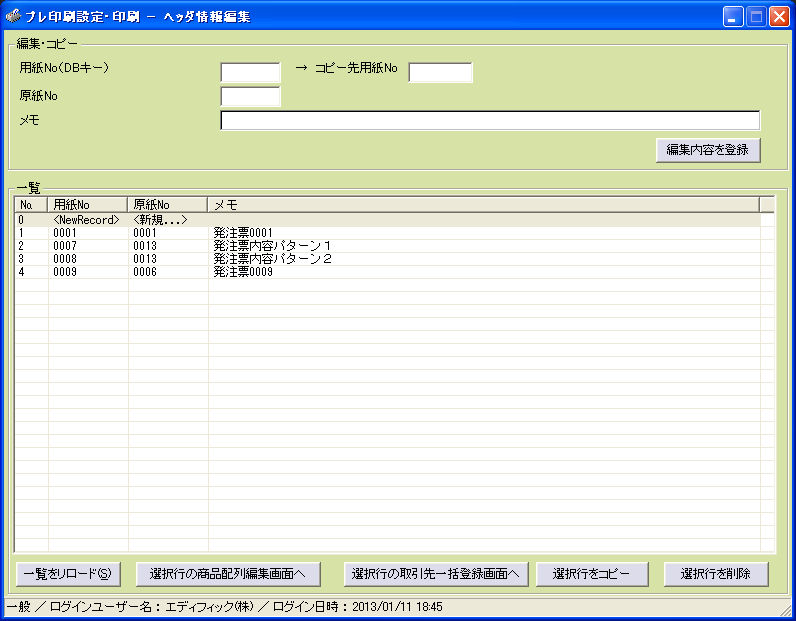
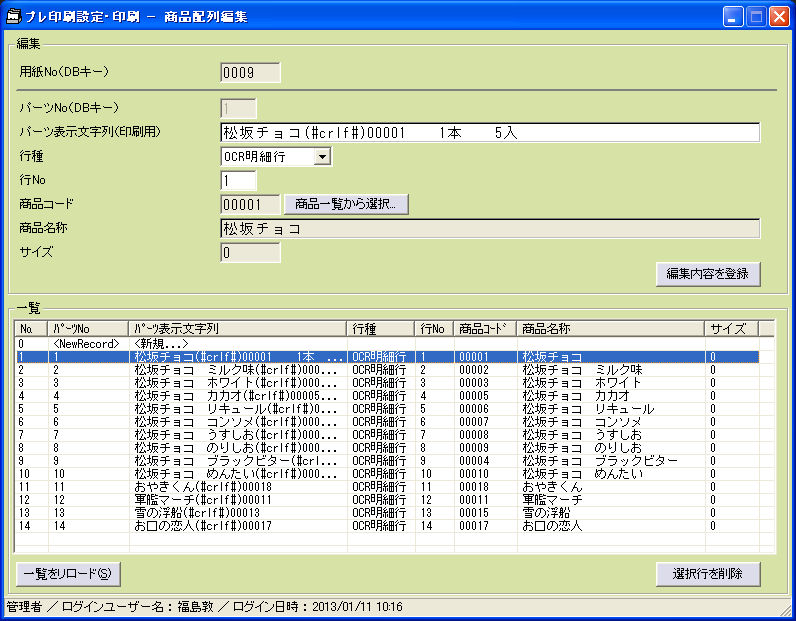
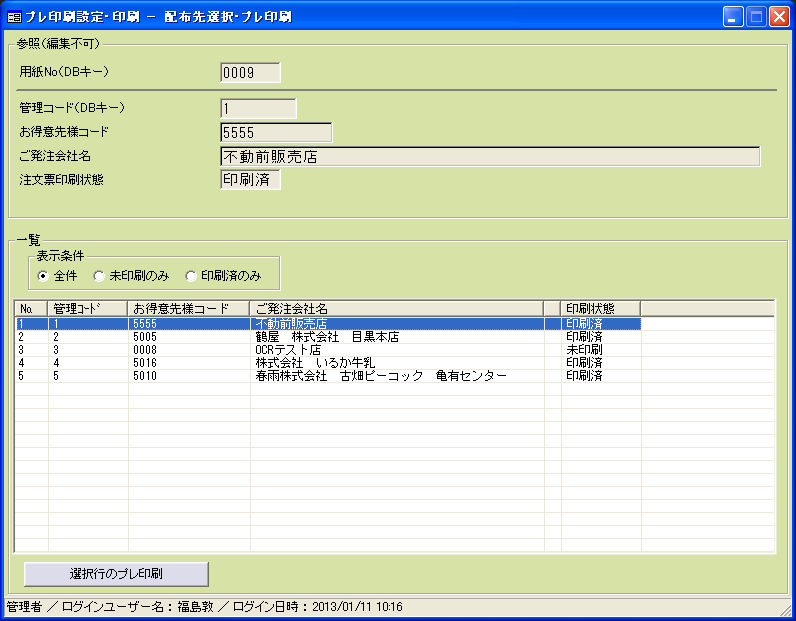
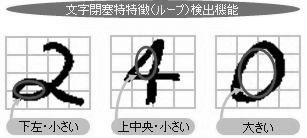
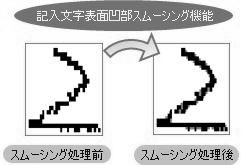
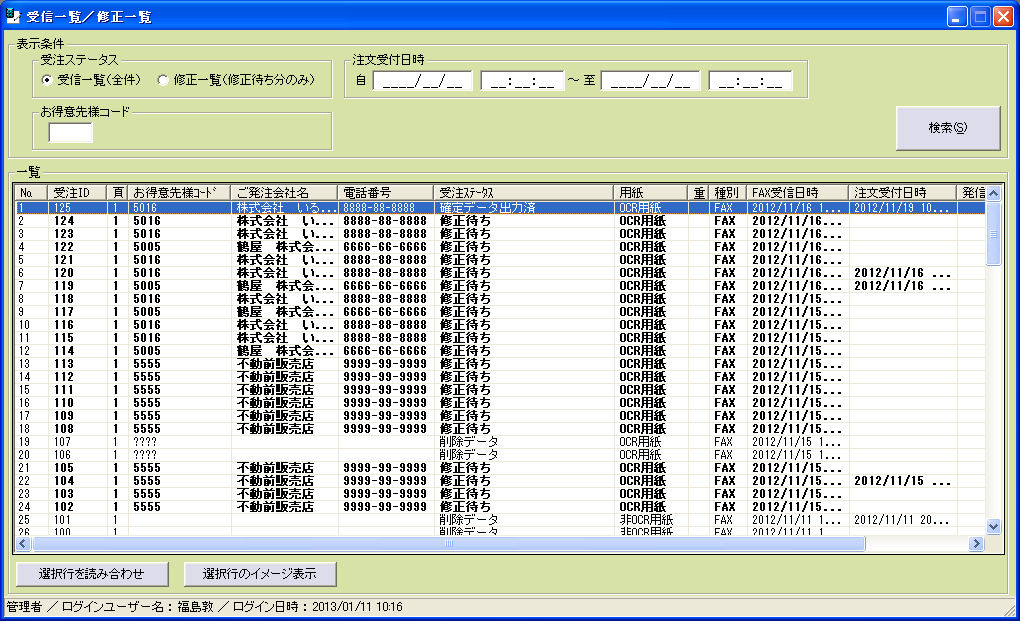
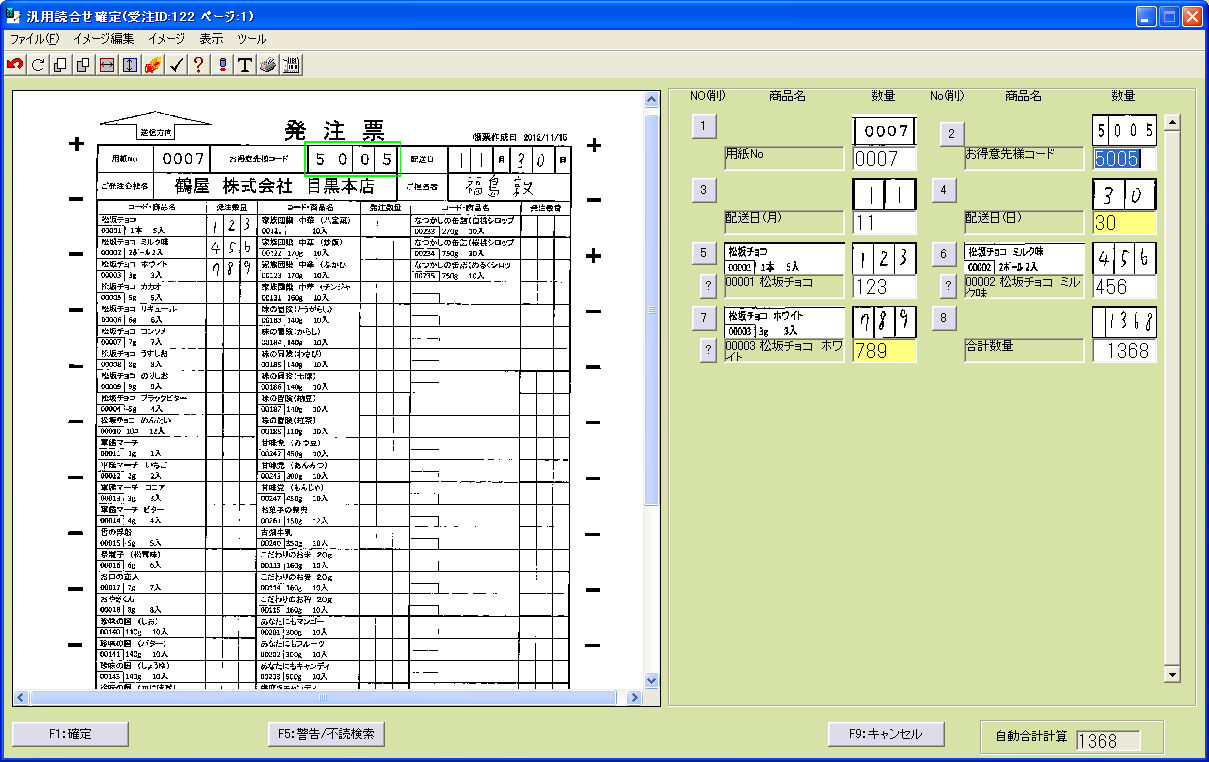
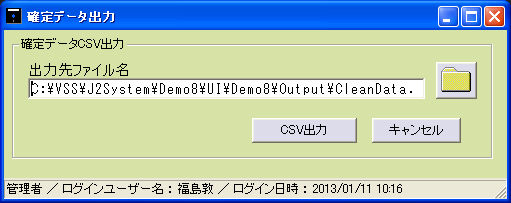
FAXの受注で、このようなことに困っていませんか?



  <ニューリリース> 貴社の悩みを解決するFAX-OCRシステム!!じゅちゅう達人 スタンダード版 FK-1特徴
機能
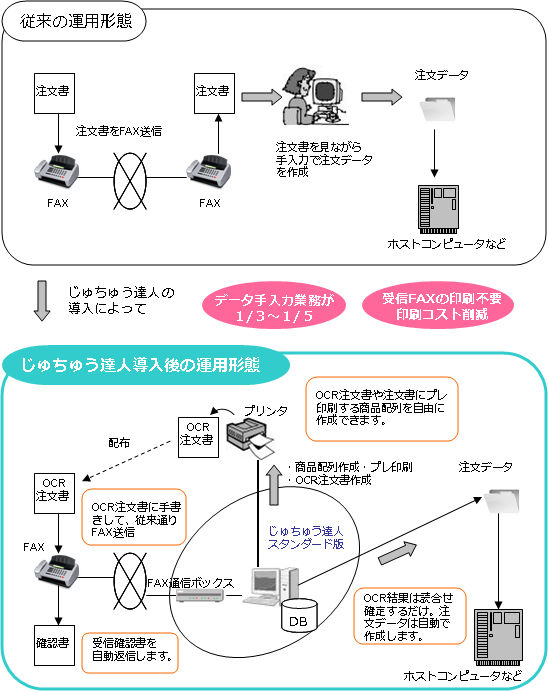
システム構成図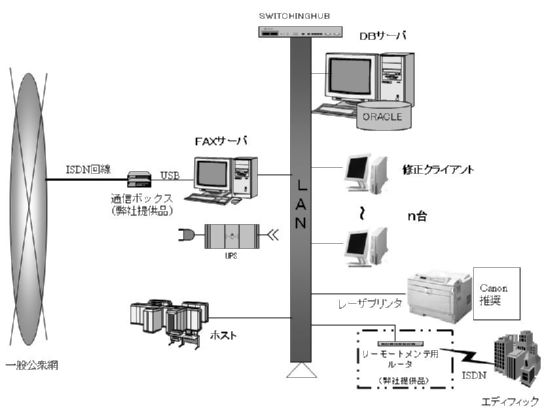
機能一覧
カスタマイズ開発対応
お問い合わせ先

資料(1):「FAXの仕組み」
資料(2):「OCRとは」
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
FAX-OCRソリューションなどで、「アナログ」と「デジタル」を「システム」で連携させます!